架构
最后于 更新
架构图
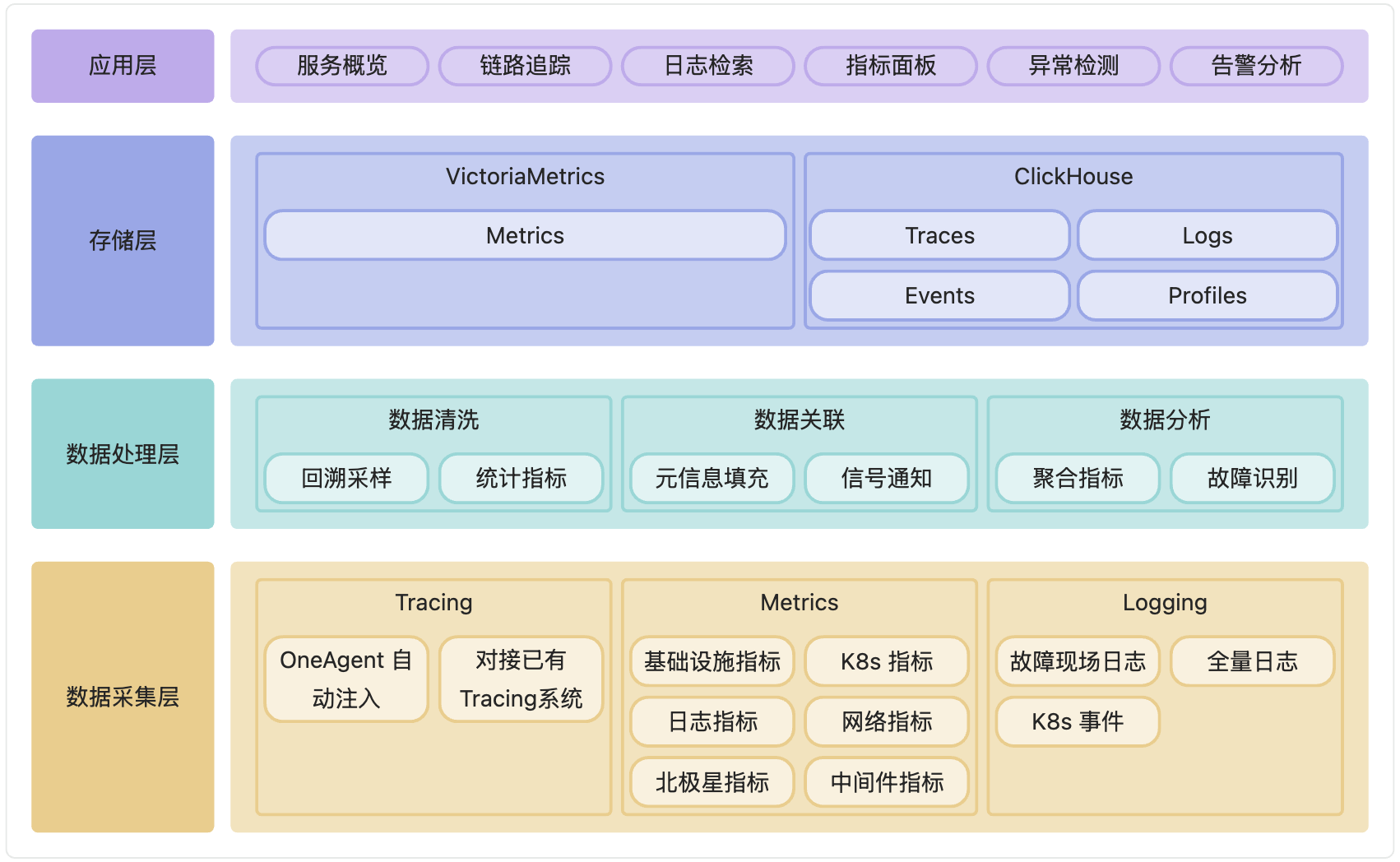
APO 的整体架构按照层次可以分成以下几层:
- 数据采集层:包括数据探针和数据采集代理,负责从各类监控系统和日志系统中收集数据。同时支持使用已有数据采集器。
- 数据处理层:对采集到的数据进行清洗、过滤和聚合,保证数据的准确性和一致性。利用机器学习和大数据分析技术,对数据进行深入分析,识别异常和故障根因。
- 存储层:采用分布式数据库和时序数据库,确保数据存储的高效性和扩展性。
- 应用层:提供可视化的用户界面,包括服务概览、链路追踪、日志检索、指标面板、异常检测、告警分析和故障排查向导等。
数据流图
APO 主要包含三部分组件,APO OneAgent、APO Proxy 与 APO Server:
- APO OneAgent:数据采集层,部署在每个被监控的主机上,用于采集 Kubernetes 集群或者虚机环境下被监控业务以及集群、主机信息。
- APO Proxy:数据处理层,部署在被监控的集群中,用于在被监控的边缘侧接收和处理数据并统一转发数据到服务端。
- APO Server:数据处理层与存储层,用于接收数据、处理数据、分析与展示数据。
下图给出了向导式可观测性产品数据采集层、数据处理层与存储层的核心数据流图:

下面分别对数据流图中的组件功能进行介绍。
APO OneAgent
- preload/odigos 用于给用户应用程序安装 Tracing 探针
- ebpf-agent 用于获取北极星指标
- ilogtail 用于采集应用程序日志数据
- node-agent 用于采集网络指标
- grafana-alloy 用于采集节点指标数据
- otel-collector-agent 用于收集 Traces 数据,统计计算服务的RED指标和数据库调用指标
APO Proxy
- nginx-proxy 用于接收各监控节点发送的回溯采样逻辑 Traces 和 Profilings,并统一转发到服务端
- otel-collector 用于采集 Kubernetes 事件;用于接收各监控节点的数据并转发到服务端;用于在指标中补充 Kubernetes 元信息
APO Server
- apo-collector 用于收集回溯采样逻辑 Traces 和 Profilings,分析数据识别链路故障,并将数据存储到 ClickHouse中
- otel-collector-gateway 在服务端统一接收 Traces、Metrics、Logs 数据
- jaeger-collector 用于接收 Traces 数据并转换为 Jaeger 的数据格式
- remote-storage 用于将 Jaeger 数据格式的 Traces 存储到 ClickHouse 中。Jaeger 1.58 不支持将链路数据直接写入 ClickHouse 并查询出来,APO修改了 Jaeger RemoteStorage,按照 Jaeger Clickhouse 项目的格式写入 clickhouse 并查询链路,目前集成的 Jaeger 版本为1.58
- jaeger-query 用于查询 Traces 数据
- ClickHouse 是一个用于在线分析处理 (OLAP) 的开源列式数据库管理系统 (DBMS)。它专为高速查询和数据分析而设计,能够在单个服务器或群集上运行,并支持实时数据流处理。ClickHouse 能够处理大量结构化数据,并且可以在几秒内完成对数十亿行数据的查询。
- VictoriaMetrics 是一款用于监控和时序数据处理的时序数据库,特别适合大规模监控场景。它的主要目标是提供高性能的时间序列存储与检索能力,同时保持较低的资源消耗。
出于可读性考虑,APO Server 使用的部分组件没有展示在数据流图中,这里给出其他组件的描述:
- apo-backend 作为应用层的 API 接口提供服务
- apo-frontend/apo-grafana 用于可视化展示数据,为应用层提供用户界面
- vmalert 用于查询 VictoriaMetrics �中的指标并产生告警
- alertmanager 用于接收告警信息并对告警进行管理,例如告警通知和告警抑制